9月13日凌晨1点,OpenAI发布o1系列模型,包括o1-preview(下称o1预览版)和o1-mini。针对这一消息,该公司创始人Sam Altman在X上表示:“no more patience, jimmy.(需要耐心等待的时刻结束了)”
* **股息权:**公司有义务在盈利时向股东支付股息。
OpenAI表示:“该模型代表了人工智能能力的新水平。鉴于此,我们将计数器重置为1,并将该系列命名为o1。”这也意味着,o1就是此前坊间盛传即将发布的“草莓”模型。
作为早期模型,o1模型还不具备ChatGPT的许多实用功能,例如浏览网页信息以及上传文件和图片。但OpenAI强调,“对于复杂的推理任务来说,这是一个重大进步。”
目前,ChatGPT Plus和Team用户已经能够在ChatGPT中访问o1模型,但每周发送消息次数限制为o1预览版30条消息和o1-mini50条消息。ChatGPT Enterprise和Edu用户将从下周开始使用这两种模式。
此外,符合API使用等级5的开发人员已经可以开始使用API中的两种模型进行原型设计,速率限制为20RPM,这些模型的API目前不包括函数调用、流式传输、对系统消息的支持和其他功能。

ChatGPT会员被分为Plus、Team、Pro三档,每月订阅价格分别为20美元、60美元(最低)、200美元。值得一提的是,就在o1模型发布前一天,OpenAI刚刚上线ChatGPT Pro会员版,售价高达200美元/月。
该公司表示,o1模型在物理、化学和生物学的具有挑战性的基准任务上的表现达到博士生水平。同时,在数学和编码方面表现出色。在国际数学奥林匹克(IMO)资格考试中,GPT-4o仅正确解决了13%的问题,而o1推理模型得分为83%;o1编码能力在Codeforces比赛中达到89%。
相较于早期模型,o1模型展示了强大的能力,美国数学邀请赛2024(AIME)中, GPT4o、o1 预览版、o1正式版的准确率分别为13.4%、56.7%、83.3%。
在Codeforces代码比赛中,GPT4o、o1 预览版、o1正式版的Codeforces准确率分别为11.0%、62%、89%。
在回答博士级科学问题 (GPQA Diamond)对比上,GPT4o、人类专家、o1的准确率是56.1%、69.7、78%。
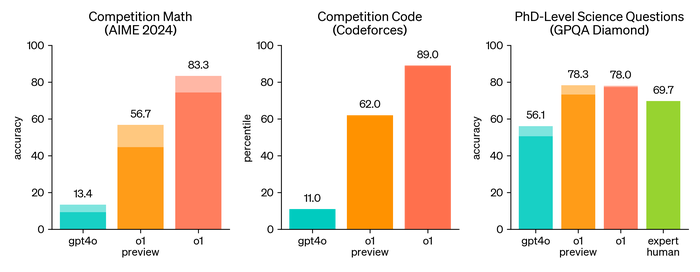 图源:OpenAI
图源:OpenAI
Sam Altman在X上表示,o1模型的的微调版本在国际信息学奥林匹克竞赛(IOI)中得分为49分,并且每个问题有10000次提交,获得金牌。
OpenAI指出,o1模型的增强推理能力在解决科学、编码、数学和类似领域的复杂问题特别有用。例如医疗研究人员可以使用o1来注释细胞测序数据,物理学家可以使用o1来生成量子光学所需的复杂数学公式,开发人员可以使用o1来构建和执行多步骤工作流程。
o1系列模型擅长准确生成和调试复杂代码。不过,OpenAI也指出,大型语言模型(例如o1)是在大量文本数据集上进行预训练的。虽然这些高容量模型具有广泛的世界知识,但对于实际应用而言,它的成本高昂且速度缓慢。
为此,OpenAI还发布了更具性价比的推理模型——o1-mini,作为一款较小的模型,o1-mini比o1预览版便宜80%。
具体到价格方面,o1预览版API每百万输入15美元,每百万输出60美元;o1-mini则是每百万输入3美元,每百万输出12美元。
作为对比,gpt-4o每百万万输入2.5美元,每百万输出10美元;gpt-4o-mini每百万万输入0.15美元,每百万输出0.6美元。
在需要推理而无需广泛世界知识的领域,o1-mini将是一种更快、经济高效的模型。OpenAI建议,ChatGPTPlus、Team、Enterprise和Edu用户可以使用o1-mini作为o1预览版的替代方案,具有更高的速率限制和更低的延迟。
o1-mini在STEM能力(自然科学、技术、工程和数学)方面,尤其在数学和编码——在AIME和Codeforces等评估基准上的表现几乎与o1相当。在一些需要推理的学术基准上,例如GPQA(科学)和MATH-500,o1-mini的表现优于GPT-4o。由于缺乏广泛的世界知识,o1-mini在MMLU等任务上的表现不如GPT-4o,在GPQA上落后于o1预览版。
在需要智能和推理的基准测试中,o1-mini的表现优于o1预览版和o1,但其在需要非STEM事实知识的任务上表现较差。
数学能力方面,在高中AIME数学竞赛中,o1-mini(70.0%)与o1(74.4%)相当,同时价格便宜得多,且成绩优于o1预览版(44.6%),o1-mini的得分(约11/15个问题)大约位列美国高中生前500名。
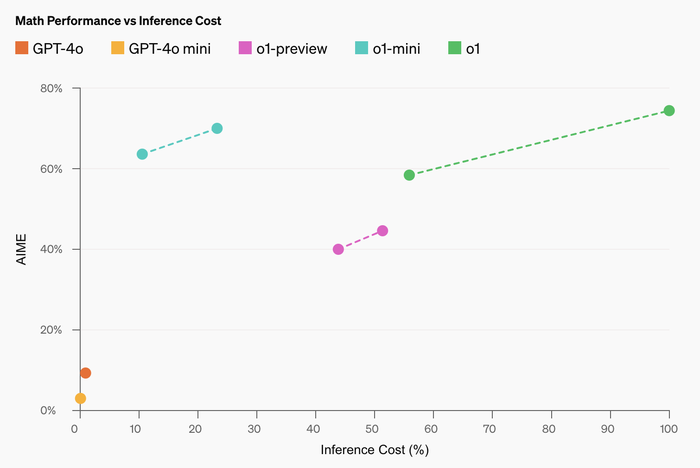 o1在高中AIME数学竞赛表现。图源:OpenAI
o1在高中AIME数学竞赛表现。图源:OpenAI
编码方面,在Codeforces竞赛网站上,o1-mini的Elo得分为1650,与o1的1673分不相上下,且高于o1预览版的1258。这一得分使该模型在Codeforces平台上竞争的程序员中处于前86%。
人类偏好评估方面,在推理能力较强的领域,o1-mini比GPT-4o更受欢迎,但在以语言为中心的领域,o1-mini并不比GPT-4o更受欢迎。
由于o1-mini专注于STEM推理能力,其关于日期、传记和琐事等非STEM主题的事实知识可与GPT-4omini等小型LLM相媲美。该公司将在未来版本中改进限制,并尝试将模型扩展到STEM之外的其他模态和专业。
OpenAI计划向所有ChatGPTFree用户提供o1-mini访问权限。除了新的OpenAIo1系列之外,该公司还计划继续开发和发布GPT系列中的模型。
该公司还特别强调了AI安全问题,为了适应这些模型的新功能,OpenAI加强了安全工作、内部管理和联邦政府合作。OpenAI最近与美国和英国的人工智能安全研究所正式达成协议。
在开发这些新模型的过程中,OpenAI提出了一种新的安全训练方法,利用它们的推理能力,使它们遵守安全和协调准则。衡量安全性的一种方法是测试当用户试图绕过安全规则(下称“越狱”)时,在最严格的越狱测试中,GPT-4o得分为22(0-100分制),而o1预览模型得分为84。
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP
责任编辑:丁文武 炒股配资选
文章为作者独立观点,不代表配资开户观点